Based Rollups
Published: 2025-03
Contributors: @eugenia_0x
In this guide you will find:
- An introduction to Based Rollups.
- Pros & Cons of Based Rollups.
- What we need to build better rollups.
- The current based landscape.
What is a based rollup?
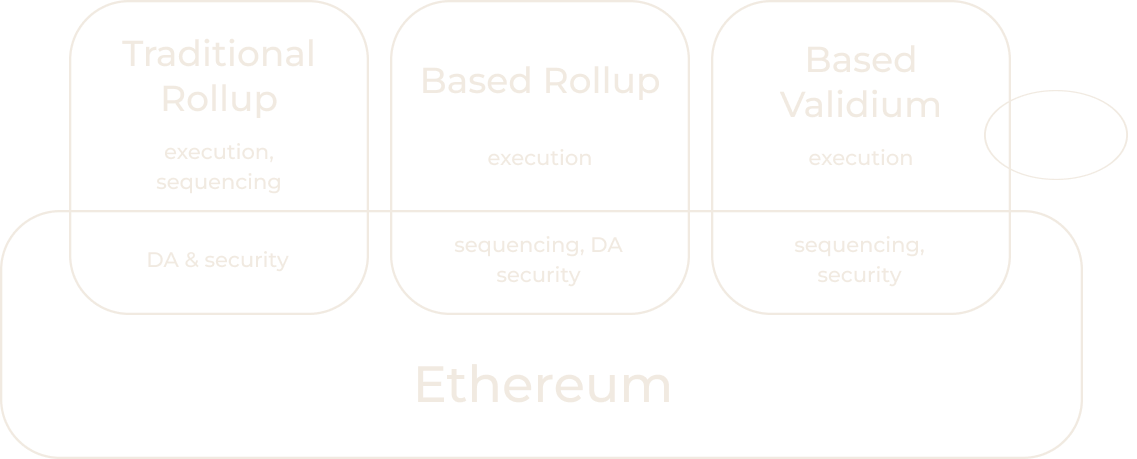
Rollups hold three different aspects: DA, consensus and execution. Based Rollups use base sequencing as the method for sequencing transactions and block building. With this method, L1 consensus (proposers, validators) holds the role to decide the ordering of transactions of the rollup.
"More concretely, a based rollup is one where the next L1 proposer may, in collaboration with L1 searchers and builders, permissionlessly include the next rollup block as part of the next L1 block."
The "based" part only speaks to its sequencing on the consensus level. Consensus of the rollup remains tied to L1 validators, while execution, state validation (optimistic or ZK) and DA is open to the design choice of each rollup team.
- Based Sequencing + Rollup Execution = Based Rollup
- Based Sequencing + Alt DA = Based Validium
- Based Sequencing + L1 (Native Rollup) = Ultrasound Rollup
All of this without any change needed to L1. In fact we already have two based rollups in mainnet: @taikoxyz Alethia and @0xFacet. However, to make better based rollups some L1, L2 and sidecar software improvements need to be implemented.
Existing rollup sequencing architecture
A centralized sequencer is easier to launch, it protects us against MEV and allows for quicker transactions (as well as low costs!).
But they introduce different drawbacks:
- They leverage trust of entities (ie, Optimism, Arbitrum)
- Introduce fragmentation issues and are intra- not interoperable (e.g. Optimism's interoperability remains within Superchain chains).
- L2s with centralized sequencers can "compete with L1", MEV can be captured by sequencers on L2.
- Not fully censorship resistant and not credible neutral: sequencers may indefinitely censor transactions – although not fully true, forced transactions are still possible.
- Are central point of failure. On traditional rollups, if a centralized sequencer goes offline or becomes unavailable, the recovery time can be too long and transaction finality can be delayed. Users must resort to L1 as an escape hatch.
Benefits of a Based Rollup
Based rollups offer a sequencing design that leverages Ethereum's own consensus mechanism, eliminating reliance on centralized entities.
Some of the key benefits include:
- Ethereum-grade liveness: If a proposer fails, the next L1 proposer simply includes the transaction. There's no centralized sequencer to halt the chain or delay finality.
- Maximal security: Based sequencing inherits Ethereum's security guarantees. (With some caveats — see "Gateways" in a later article.)
- Economic alignment: MEV flows back to Ethereum, preserving and reinforcing L1 network effects rather than fragmenting them.
- Synchronous composability: Based rollups can access and react to L1 state within the same block, enabling seamless inter-rollup and L1↔L2 interactions — no bridges, no delays.
- Infra reuse: Apps can rely on L1-native tooling (like oracles) without duplicating infrastructure. This is especially valuable for smaller appchains that can't afford to build everything from scratch.
- No token-based sequencing overhead: Since Ethereum does the sequencing, there's no need to verify L2 signatures or maintain separate escape hatches — reducing complexity and attack surface.
- Asset resilience: If a based rollup shuts down, its assets don't immediately go to zero. Value can persist on Ethereum itself (e.g. Base's memecoins, Zora's NFTs).
Drawbacks of a Based Rollup
While based rollups offer strong alignment with Ethereum, they also come with important trade-offs:
- L1 performance constraints: Tying sequencing to Ethereum means inheriting its block times and upgrade cycles. Transactions confirm every ~12 seconds by default. Preconfirmations can mitigate this, offering faster UX despite the base latency.
- Architectural complexity: Based rollups require significant engineering effort — redesigning validator subsets for sequencing, supporting preconfirmations, and building gateway mechanisms adds considerable complexity to implementation.
- Loss of sequencer revenue: Centralized sequencers today generate fees and extract MEV. Based rollups shift that revenue to Ethereum validators, reducing potential earnings for rollup teams or token-based ecosystems.
- Data availability bottlenecks: Based rollups depend on Ethereum for DA. A highly active rollup may face elevated fees or need to limit throughput due to limited L1 block space — unless using alternatives like AltDA providers (e.g. @rise_chain).
- Design flexibility is still essential: Not all rollups will—or should—go based. The broader ecosystem must support a variety of sequencing models to meet different project needs and trade-offs.
A Short Note on Synchronous Composability
Using Ethereum consensus for sequencing enables synchronous composability — effectively giving rollups the benefits of a shared sequencer. Since Ethereum builds both L1 and L2 blocks simultaneously, actions in an L1 block can immediately impact the rollup.
This allows contracts to call other contracts within the same block, interact across rollups, and move liquidity seamlessly between chains — all without added bridging complexity or latency.
- 👍 Less fragmentation across rollups and apps
- 👍 Seamless user experience with unified state access
- 👍 Improved developer experience — fewer cross-chain workarounds
- 👎 ~12 second soft confirmation times, tied to Ethereum's block cadence. Centralized sequencers already solved this; based rollups will need preconfirmation mechanisms to match that speed.
Sequencing Design Options
Different teams are exploring how to implement based sequencing in various ways. Below is a comparison of different approaches:
| Model | Sequencer Election | Preconfirmations | MEV Handling | Examples |
|---|---|---|---|---|
Total Anarchy | None | No | Leaks to L1 | Taiko model, Originally proposed by Justin Drake and referenced by Vitalik. |
Vanilla Based Sequencing | Random election of proposers before block | Yes | Sequencing MEV is captured by L1 proposer (hard to quantify) | Lime Chain |
Complex Sequencer Election | Auction-based in-between layer; not direct delegation | Yes | Measurable, design-dependent | Gwyneth, Spire, Espresso |
Block Building Design
Block building design helps explain why preconfirmations are necessary for performance and composability:
| Model | Built | Block Times | Composability | Examples |
|---|---|---|---|---|
| Total Anarchy | Locally in L2, anyone can propose to L1 | Up to 12s (matches L1 worst-case) | Dependent on L2 block time | Taiko Alethia |
| Opt-in Proposers | Subset of L1 proposers opt into a Gateway registry | Potentially sub-12s if bootstrapped more than 20% validators | Atomic & synchronous composability | Everyone else, future Taiko (not Facet) |
To enable fast composability and inclusion confidence, we need: high-performance validators + preconfirmations.
What Do We Need for Based Rollups?
- Preconfirmations: Users need confidence their transactions will be included. With optimized proving, preconfirmations can match centralized sequencer UX (100ms). However, proposer assignment and tip negotiation are non-trivial problems.
- Inclusion Lists: Allow validators to force builders to include transactions they've preconfirmed. This ensures delivery and avoids censorship.
- Inclusion logic gets tricky (e.g., swap txs vary by price).
- Requires additional validity and inclusion correctness proofs.
- Coordination: Based composability only works if others use it too. Tools and infrastructure should support rollup teams in the transition.
- Slashing: For credible commitments, validators must be slashable (e.g., via restaking protocols) if they violate preconfirmation promises or omit transactions.
- Data Availability (DA) Improvements: Based rollups depend on cheap Ethereum DA. To remain competitive, we must increase blob capacity and throughput to avoid rollup fee spikes or forced throughput limits.
- Faster Proving: Validity proofs must be included quickly in L1 to finalize L2 blocks. Current bottlenecks (e.g., in ZK rollups) can be eased by TEEs, ZK ASICs, or intermediate finality layers like Espresso. Delaying proof introduces risk of invalid block finality stalls.
The Road to (Better) Based Rollups
How can we reduce confirmation times while maintaining security guarantees —without introducing centralization?
Based Preconfirmations
Preconfirmations are commitments from validators to users, guaranteeing that a transaction will be included. They can be interpreted as execution futures: the sequencer "sells" inclusion, priced to reflect expected MEV. Preconfirmations are also commitments to Ethereum's actual future state.
Main goal: L1 proposer confirms L2 transactions
Without preconfirmations, based rollups inherit Ethereum's ~12s confirmation delay. Preconfs are essential to make based rollups competitive with centralized sequencers.
- 👍 Faster confirmation times
- 💫 Stronger assurances and credible commitments
- 🥴 If poorly designed:
- Limited confirmation availability
- Higher latency
- Slower blocks and reduced composability with other chains
Another alternative to achieve faster confirmations is reducing L1 block time (e.g., from 12s to 2s). But this raises bandwidth and sync demands on validators, which favors large-scale operators over home stakers — threatening decentralization.
There is no consensus on a single design yet. Open questions remain around execution tickets, validator auctions, and sequencing mechanics — with different teams exploring different paths.
How Confirmations Work
Preconfirmations use the Beacon Chain's "lookahead" feature — validators know the next proposer for one epoch (32 slots).
In this design:
- The user (or dApp) sends an RPC request to the upcoming sequencer proposer requesting transaction inclusion.
- If a
promiseis returned, the user now has a preconfirmation that their transaction will be included. - This confirmation is gossiped across the network so that the next includer proposer can fulfill it.
Sequencer proposers should only confirm up to ~30M gas to avoid overcommitting more than a single slot can fit.
Proving
In based rollups, a block must be proved before the next one can be created. This means every new block includes the proof for the previous one — and proving becomes a bottleneck.
SNARK proofs currently take several minutes to generate, meaning user transactions may not be considered complete until much later. This is a critical challenge.
Real-time proving could unlock major benefits:
- Native synchronous composability across L1 and L2
- More time left for building the block (faster iteration)
- Enables programmable shards or native rollups with EVM equivalence
- Higher block throughput
Goal: Fast proving and aggregation → post transaction proofs to L1 faster
Real-time or near real-time proving enables real-time settlement, increasing the synchrony window within a block. More transactions can be composable and confirmed in the same block.
Proving speeds could be improved via alternative staking networks — but ZK rollups may still face challenges in proving state transitions efficiently. Hardware matters here: GPUs, ASICs, or other accelerators drastically reduce proving latency.
There's much more to be explored about the role of hardware in enabling faster based rollups — but for now, let's look at the current landscape.
Based Rollup Landscape
This is not meant to be an exhaustive list, but rather a snapshot of the landscape as of March 2025.
| Project | Is Fork? | DA | Sequencer & Preconfs | Proving System | Comments |
|---|---|---|---|---|---|
Taiko (Alethia) | No | Ethereum | Proposer not elected beforehand; sequencer ≠ proposer. No preconfs — waits for L1 inclusion. Will integrate Nethermind AVS. | – | Uses public mempool. |
Gwyneth (Taiko) | No (boosted rollup incubated by Taiko) | Ethereum | Complex Sequencer Election model with preconfirmations. | Real-time proving + multiprover system for synchronous L1 calls. | Exploring TEEs for cross-L2 txs. High throughput via parallelism — many identical L2s to spread load (low hardware reqs). |
Facet | Optimism fork | Ethereum (state roots not posted to L1) | Forced inclusion similar to L1 guarantees. No preconfs. | – | Sovereign rollup. |
Spire | OP Stack (with major mods) | Ethereum | Complex Sequencer Election model with preconfirmations. | – | Will open source the stack to enable reuse. |
Rise | OP Stack + Rust on Reth | Alt DA | Preconfirmations | – | Aims to handle giga gas (high perf. L2). Uses Verkle trees (not ultrasound compatible). |
Puffer Unify | No (optimistic-based rollup) | Ethereum | Sequencing via Puffer LRT validators. Preconfirmations with Puffer Slasher AVS. Preconfs guarantee outcome (mitigates MEV). | Own prover infra, block proving on Intel SGX (TEE) | LSTs accessible without bridging. Native yield via LRT. |
Surge (Nethermind) | Taiko fork | Ethereum (assumed) | Preconfirmations via Nethermind AVS | – | Likely to become infra layer for launching based rollups. |
Rogue | No | Ethereum | TBD Preconfirmations planned | STARKs with KZG wrapper Includes mining mechanism via proving | Uses ethrex (Rust client by LambdaClass).Aiming for native EVM compatibility. |
Name Chain (ENS) | TBD | TBD (likely Ethereum) | No need for sequencer | TBD | – |